

近年,ChatGPTや画像・動画生成AIの登場で『AI』は一気に身近になりました..
でも,いざ「どうやって動いているの?」と聞かれると,説明がむずかしい…….
本記事では,むずかしい数式を使わずに,生成AIが自然な回答を生成するプロセスを“日常の感覚”で理解できるように解説します.
(この記事では、生成AIのことを、聞き馴染みのあるChatGPTと呼ぶことにします。)
AIについて気になる方や学校で習っているけど躓いている方がいましたら,このシリーズを読んでみてください.
〈この記事でわかること〉
・ChatGPTってそもそも何?
・ChatGPTが自然に会話できる理由
・ChatGPTの回答を生成するプロセス
ChatGPTの仕組みを超簡単に説明
まず,ざっくりと一言で説明すると…
ChatGPTってそもそも何かというと,人間の入力した単語の次に何の単語が当てはまるかを確率的に予測するシステムです.
え?どういうこと?確率を計算するって何?
例を挙げるとわかりやすいです.
例.ChatGPTに「私はリンゴを〇〇.」と入力すると,
ChatGPTは
食べる → 82%
好き → 13%
買う → 5%
のように〇〇に入る候補の確率を計算し,最も確率の高い「私はリンゴを食べる」と解答します.
この“小さな予測の積み重ね”が,自然な会話や長い文章を成立させています.
なぜ自然に会話できるの?
え,確率を計算?ほんとにこれで複雑な会話ができるの?.
この謎を解く鍵は 「膨大な読書量」+「文脈を掴む仕組み」 にあります.
- ChatGPTは,人間が書いた文章(会話、教科書、記事、プログラムなど)をとてつもない量(何兆文とか)読んでいます.
- 読む過程で,「この言葉の後には、こういう表現が来やすい」という言葉のパターンを覚えます.
- さらに,その過程の中では文脈を掴む仕組み(後で詳しく説明)が動いていて,
「この単語は、文の中のどこと強く関係しているか?」を数値で評価しています.
その結果,複雑な文章でも話の流れに沿った“それっぽい”答えを組み立てられるのです.
例を挙げると,
①ChatGPTに「彼氏と別れちゃった」って入力すると,
②学習してきた人間の会話パターンを参照して、次に続く文を確率的に予測します.
「どしたん話聞こか」→49%
「それは彼氏さんが悪いなぁ」→48%
「それは君が悪い」→3%
③回答の候補の中から確率の高いものを返答します.
ChatGPT:「どしたん話聞こか」
みたいな感じにChatGPTは「正解を知っている」わけではなく、人間がよく使う文脈を再現することで,自然な会話を成立させています.
ChatGPTの仕組みをもう少し詳しく
ここまでの説明で,「ChatGPTは膨大な学習データを元に,自然な会話ができる回答を確率的に予測している」ということは分かりました.
では,その予測はどんなプロセスで行われているのかを,少しだけ深掘りしてみましょう.
ChatGPTがテキストを入力されてから,回答を生成するまでの流れは3ステップあります.
- 入力されたテキストを理解しやすいものに整理する.
- 整理した文章を理解する.
- 理解した文章から自然な回答を確率的に予測する.
図にすると,このようなイメージです.

先ほどは,この3番「確率的に予想する」仕組みについて簡単に説明しました.
なので,ここからは詳細なプロセスについて説明します.
①入力されたテキストを理解しやすい形に整理する
人間は文字で書かれている文章を理解できますが,機械は理解できません.なので,機械が理解できるように文字を数列に変換する必要があります.
トークン化
まずは,文章を単語に分割します.
文章を単語など(トークン)に分割することをトークン化と言います.
例.15万円のカメラは安い.
→ [15 ,万円 ,の ,カメラ ,は ,安い . . ]
トークンの並びこそが,ChatGPTにとっての「言葉のデータ」になります.
ID化
次に,各トークンを語彙IDに置き換えます.
ChatGPTには数万語規模の語彙表が存在し,その語彙表から対応するIDに変換されます.
これは単純に「犬」って単語なら「1」って表すことにしよう!みたいな感じです
例.[15 ,万円 ,の ,カメラ ,は ,安い . . ]
→ [16, 5912 , 34, 8820, 22, 7431, 91]
※ これらの数字は実際のIDではなくイメージです.
これによって,単語を数列に変換することができます.
②整理した文章を理解する
文章を単語(トークン)に分割し,単語をIDによって認識できるようになったので,次は単語の意味を理解していきます.
単語の意味を理解する(ベクトル化)
ChatGPTがどのように単語の意味を理解しているかというと,ベクトル(数の配列)に変換することで単語の意味を多次元空間の点として認識しています.(そもそもベクトルとは?)
え,多次元空間の点?どういうこと?
例を挙げて説明します.
例.「犬」と「猫」を「大きさ」と「可愛さ」の二つの要素でベクトル化してみると,
「犬」→大きさ:30cm,可愛さ:90点→(30,90)
「猫」→大きさ:25cm,可愛さ:80点→(25,80)
これで大きさと可愛さの要素でベクトル(数字の配列)化できました.
これを空間の点として表してみると,このようになります.
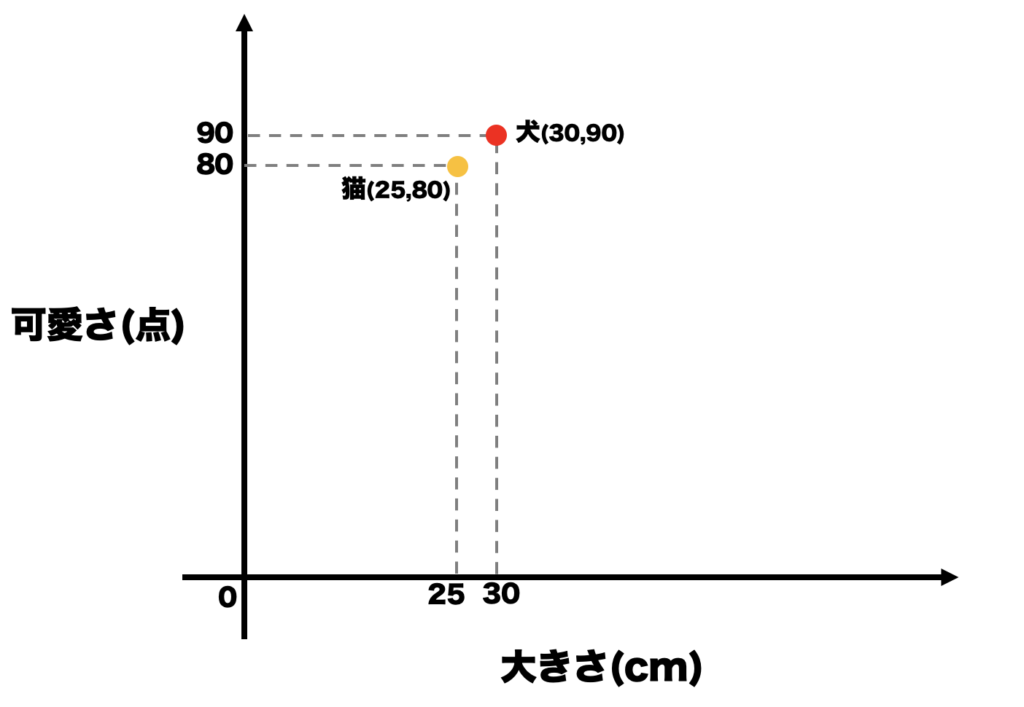
このように,「犬」と「猫」を大きさと可愛さの2次元(2つの要素)で表わされる空間に点として表すことができました,
なるほど.でも,ベクトル化(多次元空間の点で表現)するとなぜ単語の意味を理解できるの?
例を挙げて説明します.
「象」もベクトル化して,点で表すと,
「象」→大きさ:2m(200cm),可愛さ:50点→(200,50)
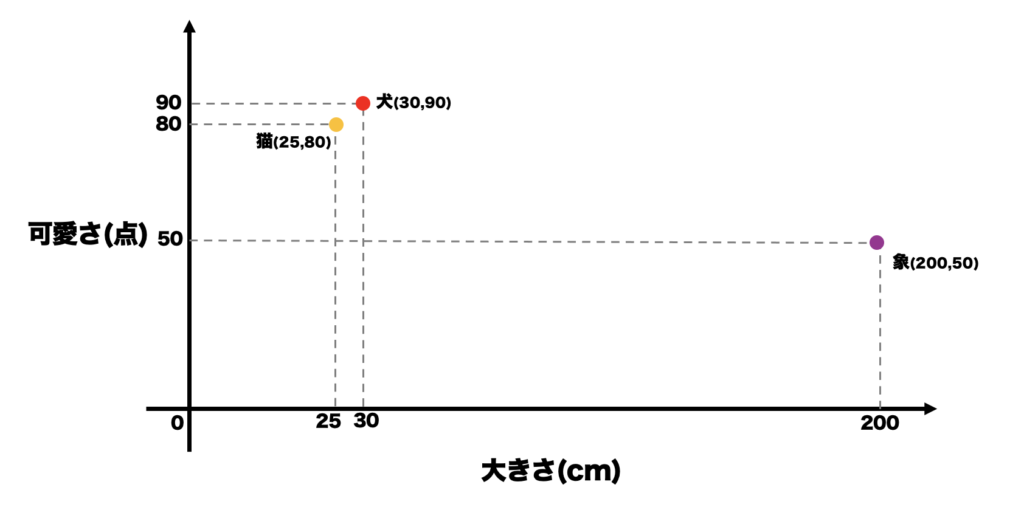
このようになります.次は,点と点の距離を見てみます.
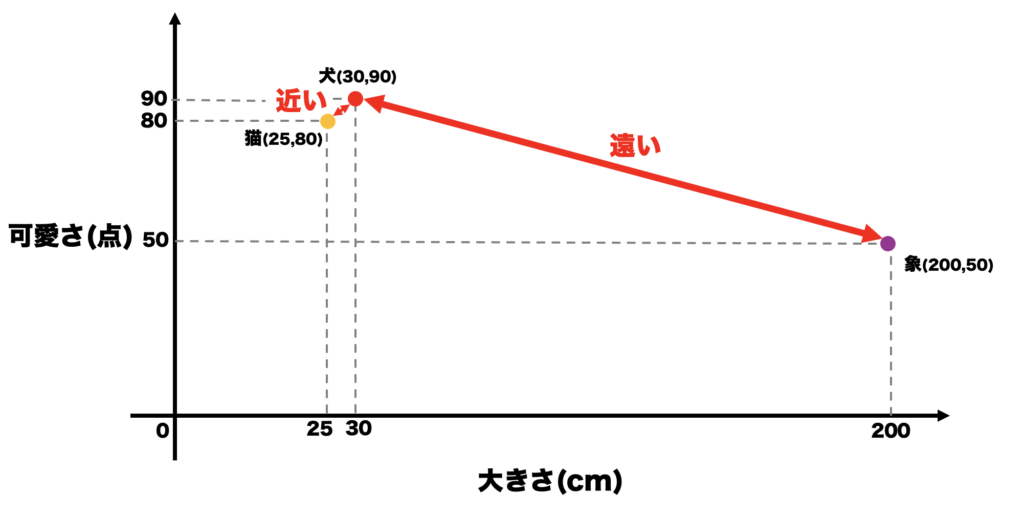
「犬」と「猫」は距離が近く,
「象」と「犬」は距離が遠い.
つまり,距離が近いと似ている単語ということがわかります.
逆に,距離が遠いと意味が近くない単語,使われ方の関連性が低い単語ということがわかります.
このように,単語を点で表し,点と点の距離などを比較することで単語の意味を理解しているのです.
※実際のChatGPTは何千もの要素で分析しており,多次元空間の点として認識しているため言葉の意味を的確に理解することができているのです.
文脈を理解する(トランスフォーマー)
次は,文脈を理解します.
ChatGPTの中核には、Googleが提案した「Transformer(トランスフォーマー)」というモデル構造(仕組み)があります.
これは,文の中で「どの単語がどの単語と関連しているか」をすべて同時に考慮する仕組みです.
このトランスフォーマー内で関連性を評価します.
例.「私はリンゴを食べる」
「私は」 ↔ 「食べる」:強く関連
「リンゴ」 ↔ 「食べる」:強く関連
「を」 ↔ 「リンゴ」:弱い関係
ChatGPTはこの関連度を「注意スコア」として数値化します.
こうして単語同士の関係性(文脈)を数値的に把握しているのです.
多層のニューラルネットワークでより理解を深める
トランスフォーマーには,この関連性を評価できるシステムが何十層〜数百層も重なっています.
各層では,前の層の情報をもとに,より高次な文脈を学習します.
例.
第1層:単語レベルの関係を理解
第2層:文の意味を理解
第3層:段落・話題レベルの流れを理解
これにより,ChatGPTは「話の全体構造」まで考慮した自然な回答を組み立てることができます.
人間が「単語 → 文 → 話の流れ」と順に理解するように,ChatGPTも層を通して段階的に意味を理解していくわけです.
③理解した文章から自然な回答を確率的に予測する
ここまででChatGPTは,入力された文章の意味や文脈を理解できるようになりました.
次のステップでは,その理解をもとにどんな言葉を返すのが最も自然かを確率的に予測して,文章を生成していきます.
確率の計算
上章で説明した通り,ChatGPTは,文の最後に続く「次の単語」の候補を複数挙げ,それぞれの出現確率を計算します.
例.ChatGPTに「私はリンゴを〇〇.」と入力すると,
ChatGPTは
食べる → 82%
好き → 13%
買う → 5%
のように〇〇に入る候補の確率を計算し,最も確率の高い「私はリンゴを食べる」と解答します.
この処理を「確率分布に基づく単語予測」といい,専門的な用語を出すと,Softmax関数を使用しています.(Softmax関数とは)
回答を生成する(デコード)
そして,ChatGPTは確率の計算を1単語ずつ繰り返しながら文章を組み立てます,
例.
「私はリンゴを」→「食べる」→「.」→「美味しかった」→…
というように,確率的な次の単語選びを何十回も繰り返すことで,自然な会話や長文を生成しているのです.
まとめ
まとめると,
- ChatGPTは「次の単語を確率で予測するAI」.
- 小さな予測を連ねて,長い文章や自然な会話をつくる.
- 自然に話せる理由は「膨大な読書量+文脈理解」.
大量のテキストから言葉の並び方(パターン)を学び,文中の関連を数値化して“それっぽさ”を再現する. - 内部プロセスは3ステップ

- 入力されたテキストを理解しやすいものに整理する.(トークン化→ID化)
- 整理した文章を理解する.(ベクトル化→トランスフォーマー)
- 理解した文章から自然な回答を確率的に予測する.(確率の計算→デコード)
ここでは,かなり簡単な内容を説明したので,「抽象化され過ぎていて分からなかった.」や「もっと詳しいことを知りたい!」などがあれば,より詳しい内容がこちらのサイトに書かれているので読んでみてください.
最後まで読んでくださり,ありがとうございました.
書いている途中に「この章いらないなぁ」って思ったけど,せっかく書いたので笑
余談:ChatGPTが嘘をつく理由
ChatGPTはいつも事実が正しいわけでありません.
なぜならChatGPTは「正しいことを言おう」としているのではなく,「一番それっぽく自然に聞こえること」を統計的に言おうとしているからです.なので「もっとも自然な文脈」になる確率が高い候補を選ぶ仕組みです.そのため,“もっともらしいけれど誤った説明”をしてしまうことがあります(これをハルシネーションといいます).
AIが嘘をつきやすい,3パターン
ここでは確率的に自然な言葉=正しい言葉になりにくいパターンを3つ,例と一緒に見てみましょう.
①本当は違うけど、ネット上ではそう書かれている情報を信用するパターン
たとえば──
「ピザは野菜」
ある時期,アメリカで「ピザは野菜扱いになった」というニュースが話題になりました.
これは,ピザそのものが野菜と認められたわけではなく,ピザソース(トマトソース)に含まれる野菜成分を野菜量の基準にカウントできるという話だったんです.
でも,そのニュースの見出しやSNS投稿ではインパクト重視で
「ピザは野菜に認定!」という表現が拡散しました.
すると,AIが学習するデータの中ではこのような分布になります.
AIが見た「確率の世界」
| 候補 | 出現頻度 | 実際の正確さ |
|---|---|---|
| ピザ=野菜 | 60% | ❌ 間違い |
| ピザソース=野菜 | 40% | ✅ 正解 |
この場合,「ピザは野菜」の方を自然な答えとして選んでしまうんです.
つまり,AIは「よく語られる話題」ほど,「信憑性が高い」と誤解してしまう.
②質問があいまいで質問の意図と違う答えを出してしまうパターン
たとえば──
「日本の中心は?」
この質問を人間が聞いたとき,思い浮かべる答えは人によって違います.
- 「政治の中心」だと思う人 → 東京
- 「地理的な真ん中」だと思う人 → 滋賀県あたり
- 「経済の中心」だと思う人 → 東京 or 大阪
質問が曖昧で,いろんな解釈ができそうです.しかし,統計的なデータから考えると「“日本の中心”という質問を見たとき、最も多く出てくるのは“東京”だな」
→ よってAIは 「日本の中心は東京です」 と回答してしまいます.
③知らないことを推論しているパターン
たとえば──
「シンデレラの靴はガラスの靴?毛皮の靴?」
有名な童話『シンデレラ』の中で,主人公が履いていたのは「ガラスの靴」と言われています.
でも実は,この“ガラスの靴”が本当にガラスだったのかどうかは,はっきり分かっていません
原作(フランス語)では「vair(ヴェール)」という単語が使われており,
これは「毛皮(フェレットの毛など)」を意味します.
ところが,この「vair(毛皮)」と発音が似ている「verre(ガラス)」が混同されたことで,
翻訳者が「ガラスの靴」と誤訳したのではないか?という説があるんです.
「本当に誤訳なのか」「それとも意図的な表現変更なのか」については,
研究者の間でも決着がついていません.
つまり,この話には「はっきりした正解がない」のです.
ここでAIがどう動くか
ChatGPTがこの質問を受け取ったときのイメージを見てみましょう
| 候補 | 出現頻度(ネット上) | 実際の正確さ |
|---|---|---|
| ガラスの靴 | 90%(童話・映画・SNSなど) | ❓ 真偽不明(でも一般的) |
| 毛皮の靴 | 10%(言語学的考察や研究論文) | ❓ 真偽不明(少数派) |
はっきりとした答えがない場合でも,「シンデレラの靴はガラスの靴である」というもっとも有名な答えを選ぶ確率が圧倒的に高くなるのです.
つまり,「正解が1つに定まらない」情報でも,世の中でいちばん多く見たパターンを再現してしまうのです.
AIに“嘘をつかせない”のは、質問力で決まる
| ポイント | 内容 |
|---|---|
| 1. あいまいにしない | 「何について?」「どんな意味で?」を明確にする |
| 2. 理由・根拠・証拠を聞く | 「なぜそう言えるのか?」を添える |
| 3. 他の説も聞く | 「他の考え方もある?」で推測の誤りを防ぐ |

コメント